
索引是帮助MySQL高效获取数据的排好序的数据结构。
mysql每页大小为16KB,查询语句:show GLOBAL STATUS like 'Innodb_page_size';
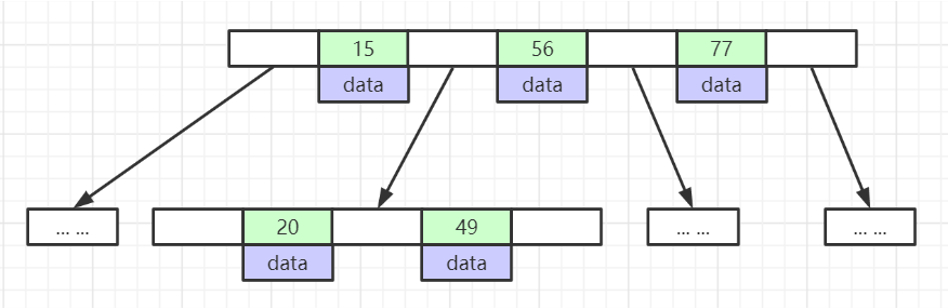
如果主键是BigInt,占8个字节,中间指针约6字节,那么一页可以存放16*1024/14 = 1170
假设数据为1KB,那么三层的树可以存放:1170*1170*16=21902400条数据。
MySql索引结构采用B+Tree和Hash。
MyISAM索引文件和数据文件是分离的(非聚集)
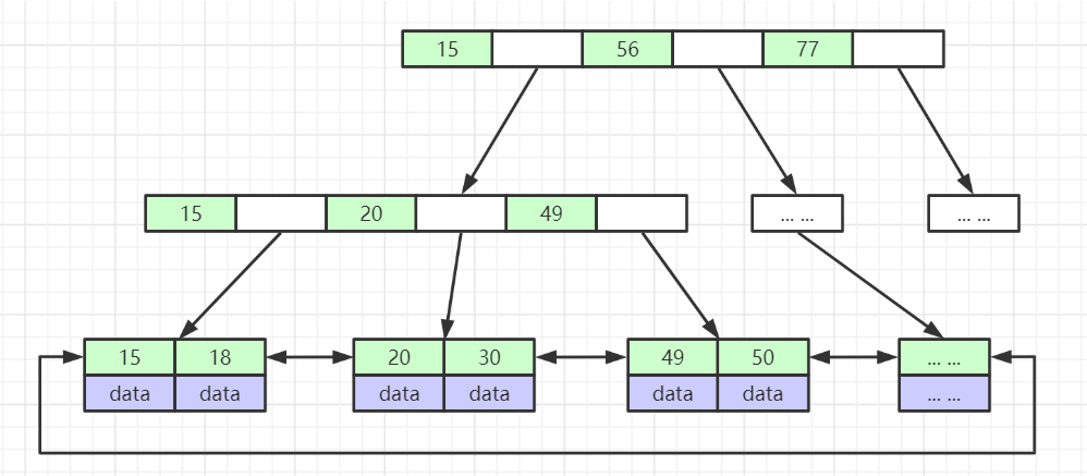
表数据文件本身就是按B+Tree组织的一个索引结构文件(聚集)
聚集索引-叶节点包含了完整的数据记录
为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键?
必须有主键才能构造出B+Tree,不设置主键会找出数据都不同的列,找不到mysql会生成一个隐藏列用来构键索引树。
非自增的话,插入的时候性能消耗更大(会导致原来的页分开,树要重新平衡),自增的话,在页数据存满的时候,在后面新增一页即可。
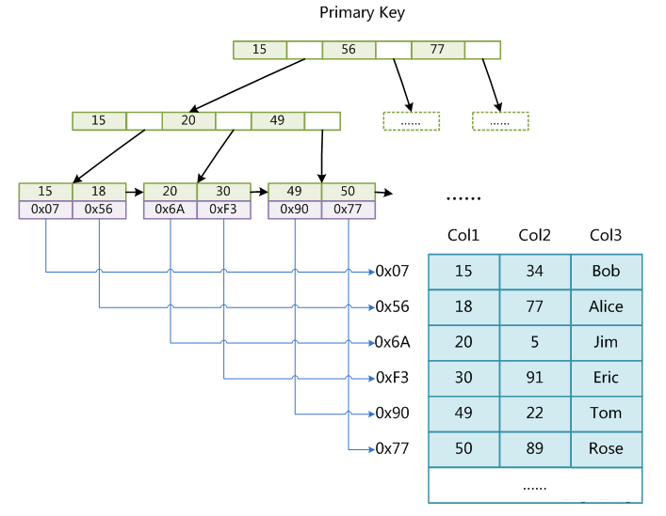
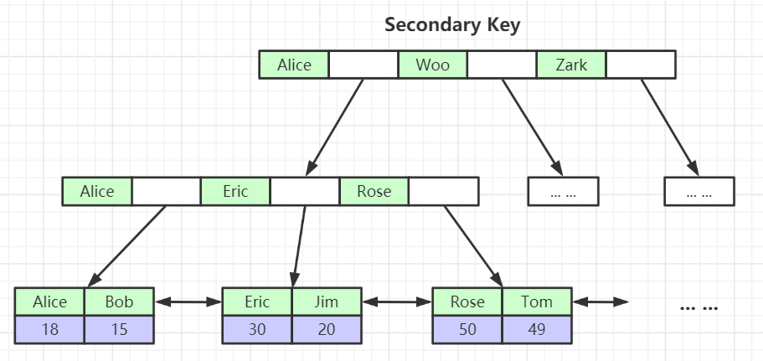
为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)
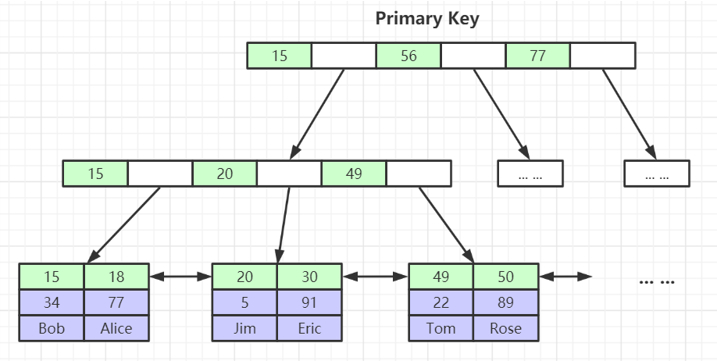
非主键索引:叶子节点上存储的是主键,找到主键再通过主键查找数据(回表)。
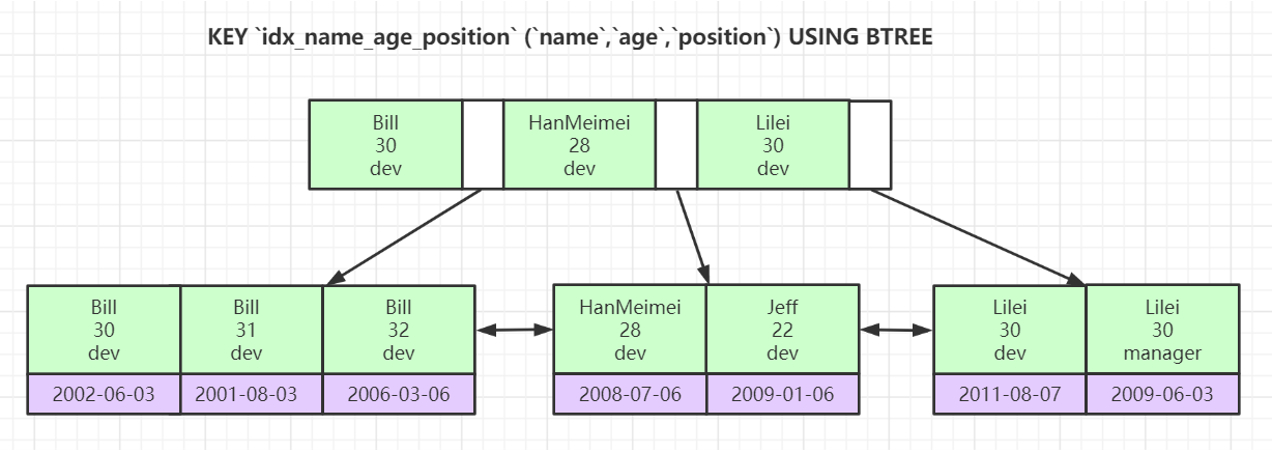
以图示为例,先比较name,再比较age,最后比较position。所以可能出现左侧age比右侧age大的情况(因为先比较的name),这就是最左匹配。
where name = 'bill' and age = 30; # 走索引
where age = 30 and name = 'bill'; # 不走索引
where position = 'dev'; # 不走索引
 日常笔记
日常笔记